|
8.2
general documentation
|


|
|
8.2
general documentation
|
|
This document presents the STUDYMANAGER (SMGR) command. The aim of this command is to drive code_saturne's cases automatically, to compare checkpoint files, to display results and to generate reports.
SMGR is a small framework to automate the launch of code_saturne computations and do some operations on new results.
The script needs a source directory of code_saturne cases, called the repository, which will be run in a destination directory.
The destination directory structure only contains the required files for SMGR functionalities. Thus, only POST, REPORT and <CASE> directories will be found in duplicated studies. In the same way, only RESU/<run_id> directories will be found in <CASE>.
For each duplicated case, SMGR can run the case, compare the obtained checkpoint file with the previous one from a reference destination repository, and plot curves in order to illustrate the computations. All generated figures are batched in report_figures.pdf. For each duplicated study, SMGR can generate the description report based on the latex file in the REPORT folder.
In the repository, previous results of computations are required only for checkpoint files comparison purposes. They can be also useful, if the user needs to run specific scripts.
SMGR is available as a code_saturne command, and does not need a specific installation: the related files are installed with the other Python scripts of code_saturne. Nevertheless, additional prerequisites which may be required are:
numpy,matplotlibSince these are used in a dynamic manner, they may be added after the code_saturne installation, and do not require any re-installation.
A complete and up-to-date list of command-line options may be obtained by running:
code_saturne smgr -h
Most command-line options are detailed here:
-h, --help: show the help message and exit-f FILE, --file=FILE: give the parameters file for SMGR. This file is mandatory, and therefore this option must be completed-q, --quiet: do not print status messages to stdout-u, --update-smgr: update the studymanager file smgr.xml in the repository-x, --update-setup: update all code_saturne setup.xml files in the repository-t, --test-compile: compile all cases in the repository-r, --run: create and run all cases in destination--state: analyze state for all cases--n-procs=N_PROCS: Optional number of processes requested for the computations-n N_ITER, --n-iterations=N_ITER: maximum number of iterations for cases of the study-c, --compare: compare results files between repository and destination-d REFERENCE, --ref-dir=REFERENCE: absolute reference directory to compare dest with-p, --post: postprocess results of computations--report: generate V&V description report-m ADDRESS1 ADDRESS2 ..., --mail=ADDRESS1 ADDRESS2 ...: addresses for sending the reports-l LOG_FILE, --log=LOG_FILE: name of studymanager log file (default value is 'studymanager.log')-z, --disable-tex: disable text rendering with LaTex in Matplotlib (use Mathtext)--rm: remove all existing run directories in destination--dow: disable overwriting files in DATA, SRC, MESH and POST directories in destination-s, --skip-pdflatex: disable tex reports compilation with pdflatex--fmt=DEFAULT_FMT: set the global format for exporting matplotlib figure (default is pdf)--repo=REPO_PATH: force the path to the repository--dest=DEST_PATH: force the path to the destination-g, --debug: activate debugging mode--with-tags=WITH_TAGS: only process runs with all specified tags (separated by commas)--without-tags=WITHOUT_TAGS: exclude any run with one of specified tags (separated by commas)--create-xml: create xml from study (current directory has to be a study)--with-resource=RESOURCE_NAME: use resource settings based on given name--slurm-batch-size=SIZE: maximum number of cases per batch in SLURM batch mode (50 by default)--slurm-batch-wtime=TIME: maximum computation time in hours per batch in SLURM batch mode (12 hours by default)--slurm-batch-arg=SLURM_BATCH_ARGS: additional sbatch arguments (use –slurm-batch-arg=<arg> to handle – in argument)--report generate description reportsample.xml, create destination directory and exit; sample.xml sample.xml ../RUNS/RIBS (RIBS} will be created, RUNS already exists). The command is launched from inside the study directory, so the repository containing the original study is simply indicated by .. report_figures.pdf is generated only if the option -p, --post is present in the command line.
write-up.pdf is generated only if the option --report is present in the command line. The content of POST folder in destination is not overwriten if the option -p, --post is not also present in the command line.
The SMGR parameter file is an XML (text) file that describes studies and cases involved in the SMGR process.
The four first lines of the SMGR parameter file are mandatory. The third and fourth lines correspond to the definition of the repository and destination directories. Note that if the destination does not exist, the directory is created.
When SMGR is launched, the parameters file is parsed in order to known which studies and cases from the repository should be copied in the destination. The selection is done with the markups <study> and <case>.
The last line of the parameters file must be:
The attributes for the studies are:
label: the name of the study;status: must be on or off to activate or desactivate the study;tags: possible tags distinguishing runs from the others in the same SMGR parameter file (ex.: tags="fine,high-reynolds"). These tags will be applied to all cases in the study.Only the attributes label and status are mandatory.
The attributes for the cases are:
label: the name of the case;run_id: name of the run directory (sub-directory of RESU) in which the result is stored. This attribute is optional. If it is not set (or if set to run_id=""), an automatic value will be proposed (run1);status: must be on or off to activate or deactivate the case;compute: must be on or off to activate or deactivate the computation of the case;post: must be on or off to activate or deactivate the post-processing of the case;tags: possible tags distinguishing the run from the others in the same SMGR parameter file (ex.: tags="fine,high-reynolds"). They are added to the study tags if they exist;n_procs: number of processes requested for the run;expected_time: expected computation time in hours (only required for SLURM batch mode).Only the attributes label, status, compute, and post are mandatory.
run_id already exists, the computation is not performed again. Use option --rm SMGR command-line to remove all existing run directories in destination.--dow SMGR command-line to disable overwriting files in POST and RESU/<run_id> directories.Note that it is possible to run several times the same case in a given study with some variations thanks to the study manager tool. This can be a very powerful tool to launch parametric studies.
There are three ways to modify a setting on-the-fly corresponding to the following nodes:
<notebook><parametric><kw_args>These nodes can be used together inside the same case. In order to modify the setup between two runs of the same case, <notebook>, <parametric> and <kw_args> nodes can be added as children of the considered <case> node. All of them use the attribute args to pass additional arguments.
In order to define different runs relying on the same case settings but with a variation of some parameters, the <case> node has to be repeated in the xml file:
If nothing is done, the case is repeated without modifications.
All these nodes apply a specific filter type during the stage (initialize) step of a case's execution (i.e. when copying data), just before the define_domain_parameters (and domain_copy_results_add) function in the cs_user_scripts.py user scripts. They only modify the copied files in the destination RESU/<run_id> directory.
<notebook> allows passing key-value pairs (with real-values) matching notebook variables already defined in the case thanks to the GUI. This will override the values in the case's setup.xml with the provided values.
code_saturne run command using the --notebook-args option.domain.notebook member of the domain object passed to these functions.The <parametric> node allows passing options handled by cs_parametric_setup.py filter to modify the case setup.
code_saturne run command using the --parametric-args option.domain.parametric_args member of the domain object passed to these functions.Here are listed the main options available through the <parametric> node
| Key | Usage |
|---|---|
-m, --mesh | set the mesh name (a string) to use |
--mi, --mesh_input | set the mesh input file (a string). This file results from a previous preprocessing stage |
-a, --perio-angle | set the angle of rotation (a float) in case of periodicity |
-r, --restart | set the restart directory (a string) to consider |
--different-restart-mesh | if set then one specifies that the restart directory corresponds to a run with a different mesh |
-n, --iter-num | set the max. number of time iterations (an integer) to be done |
--tmax | set the final time (a float) of the simulation |
--iter-dt | set the value of time step (a float) |
--imrgra | set the algorithm (an integer) for the gradient reconstruction. See the imrgra documentation in cs_equation_param_t (part related to the legacy settings) for more details or the theory guide. |
--blencv | value (a float) between 0 and 1. Set the portion of centered scheme (0: induces an upwind scheme). This is done variable by variable <var>:<val>. See the blencv documentation in cs_equation_param_t (part related to the legacy settings) or the theory guide. |
<kw_args> allows passing additional user options to define_domain_parameters and domain_copy_results_add in cs_user_scripts.py.
code_saturne run command using the --kw-args option.domain.kw_args member of the domain object passed to these functions.domain.meshes, domain.restart, and similar members of the domain argument should be modified directly, rather than modifying the setup.xml file, as the matching values have already been read and assigned to domain at this point.On a cluster using the SLURM resource manager, SMGR can be configured to submit batches of cases rather than running them in succession. All cases are automatically sorted by number of processes and level of dependency, and grouped by blocks of cases of similar characteristics (to avoid submitting too many small jobs).
Job-dependencies are defined automatically such that blocks of dependency level M will wait until all blocks of level M-1 are successfully finished.
This is activated by defining N > 0 or M > 0 using the following command-line options:
--slurm-batch-size=N--slurm-batch-wtime=MA more detailled explanation of the SLURM batch mode is given in the dedicated page : How to submit cases on cluster with SLURM
wckey argument should be defined. It can be done by either using --slurm-batch-arg=--wckey=<key> during run time, or by setting an environnement variable with the following command: export SBATCH_WCKEY=<key>.The comparison is activated if the option -c, or --compare is present in the command line. A markup <compare> must also be added in the SMGR parameter file as child of the considered case.
In the above example, a checkpoint file comparison is switched on for the case Grid1 (for all variables, with the default threshold), whereas no comparison is planned for the case Grid2. The comparison is done by the same mechanism as the code_saturne bdiff command.
The attributes for the comparison are:
repo: id of the results directory in the repository for example repo="20110704-1116"; if there is a single results directory in the RESU directory of the case, the id can be omitted: repo="";dest: id of the results directory in the destination:dest="", and the value will be updated after the run step in the destination directory (see section about [restart](Output files));code_saturne smgr -f sample.xml -c for example), the id of the results directory in the destination must be given (for example dest="20110706-1523"), but if there is a single results directory in the RESU directory of the case, the id can be omitted: with dest="", the id will be completed automatically;args: additional options for the code_saturne bdiff command or underlying cs_io_dump tool:--section: name of a particular variable;--threshold: real value above which a difference is considered significant (default: *1e-30* for all variables);status: must be on or off to activate or desactivate the comparison;Only the repo, dest and status attributes are mandatory.
Several comparisons with different options are permitted:
Comparison of results will be summarized in a table in the file report_detailed.pdf (see output section):
| Variable Name | Diff. Max | Diff. Mean | Threshold |
|---|---|---|---|
| VelocityX | 0.102701 | 0.00307058 | 1.0e-5 |
| VelocityY | 0.364351 | 0.00764912 | 1.0e-3 |
Alternatively, in order to compare all activated cases (status at on) listed in a SMGR parameter file, a reference directory can be provided directly in the command line, as follows:
code_saturne smgr -f sample.xml -c -d /scratch/***/reference_destination_directory
The main objective of running external scripts is to create or modify results in order to plot them. The launch of external scripts is activated if the option -p, --post is present in the SMGR command line. All postprocessing scripts must be in the POST directory from the current study in the repository.
The markup <script> has to be added as a child of the considered case in the SMGR parameter file.
The attributes are:
label: the name of the file of the considered script;status: must be on or off to activate or deactivate the markup;args: the arguments to pass to the script;repo and dest: id of the results directory in the repository or in the destination;dest=""), and the value will be updated after the run step in the destination directory (see output section).RESU directory (either in the repository or in the destination) of the case, the id can be omitted: repo="" or dest="", the id will be completed automatically. If attributes repo and dest exist, their associated value will be passed to the script as arguments, with options "-r" and "-d" respectively.Only the label and status attributes are mandatory.
Example of a script which searches printed information in the listing, (note the function to process the passed command line arguments):
The purpose of this functionality is to create new data based on several runs of cases, and to plot them (see 2D plots) or to insert them in the final detailed report (see post-processing input).
The <postpro> markup must to be added as a child of the considered study.
The attributes are:
label: the name of the file of the considered script;status: must be on or off to activate or deactivate the markup;args: the additional options to pass to the script;Only the label and status attributes are mandatory.
The options given to the script in the command line are:
-s or --study: label of the current study;-c or --cases: string which contains the list of the cases;-d or --directories: string which contains the list of the directories of results.Note that all options must be processed by the script itself. Several calls of the same script or to different scripts are permitted.
The post-processing is activated if the option -p or --post is present in the command line.
The following example shows the drawing of four curves (or plots, or 2D lines) from two files of data (which have the same name profile.dat). There are two subsets of curves (i.e. frames with axis and 2D lines), in a single figure. The figure will be saved on the disk in a pdf (default) or png format, in the POST directory of the related study in the destination. Each drawing of a single curve is defined as a markup child of a file of data inside a case. Subsets and figures are defined as markup children of <study>.
The plots of computational data are built from data files. These data must be ordered as column and the files should be in results directory in the RESU directory (either in the repository or in the destination). Lines starting with character \# are treated as as comments.
In the parameters file, curves are defined with two markups: <data> and <plot>:
<data>: child of markup <case>, defines a file of data;file: name of the file of datarepo or dest: id of the results directory either in the repository or in the destination;dest="", and the value will be updated after the run step in the destination directory (see [output](Output files) section).RESU directory (either in the repository or in the destination) of the case, the id can be omitted: repo="" or dest="", and it will be completed automatically.The file attribute is mandatory, and either repo or dest must be present (but not both), even if they are empty.
<plot>: child of markup <data>, defines a single curve; the attributes are:spids ids of the subset of curves (i.e. markup <subplot>) where the current curve should be plotted (whitespace-separated list);xcol: number of the column in the file of data for the abscissa;ycol: number of the column in the file of data for the ordinate;legend: add a label to a curve;fmt: format of the line, composed from a symbol, a color and a linestyle, for example fmt="r--" for a dashed red line;xplus: real to add to all values of the column xcol;yplus: real to add to all values of the column ycol;xscale: real to multiply to all values of the column xcol;yscale: real to multiply to all values of the column ycol;xerr or xerrp: draw horizontal error bar (see section on error bars);yerr or yerrp: draw vertical error bar (as above);markevery="2" or markersize="3.5". These options are summarized in the table smgr_table_curves. Note that the options which are string of characters must be encased in quotes like this: ‘color="'g’"`.| Property | Value Type |
|---|---|
| alpha | float (0.0 transparent through 1.0 opaque) |
| antialiased or aa | True or False |
| color or c | any Matplotlib color |
| dash_capstyle | butt; round; projecting |
| dash_joinstyle | miter; round; bevel |
| dashes | sequence of on/off ink in points ex: dashes="(5,3)" |
| label | any string, same as legend |
| linestyle or ls | -; --; -.; :; steps; ... |
| linewidth or lw | float value in points |
| marker | +; ,; .; 1; 2; 3; 4; ... |
| markeredgecolor or mec | any Matplotlib color |
| markeredgewidth or mew | float value in points |
| markerfacecolor or mfc | any Matplotlib color |
| markersize or ms | float |
| markevery | None; integer; (startind, stride) |
| solid_capstyle | butt; round; projecting |
| solid_joinstyle | miter; round; bevel |
| zorder | any number |
The attributes spids and ycol are mandatory.
In case a column should undergo a transformation specified by the attributes xscale,yscale,xplus,yplus, scale operations take precedence over translation operations.
Details on 2D lines properties can be found in the Matplotlib documentation. For more advanced options see Matplotlib raw commands.
A subset of curves is a frame with two axis, axis labels, legend, title and drawing of curves inside. Such subset is called subplot in the Matplotlib vocabulary.
<subplot>: child of markup <study>, defines a frame with several curves; the attributes are:
id: id of the subplot, should be an integer;legstatus: if "on" display the frame of the legend;legpos: sequence of the relative coordinates of the center of the legend, it is possible to draw the legend outside the axis;title: set title of the subplot;xlabel: set label for the x axis;ylabel: set label for the y axis;xlim: set range for the x axis;ylim: set range for the y axis.For more advanced options see Matplotlib raw commands.
Figure is a compound of subset of curves.
<figure>: child of markup <study>, defines a pictures with a layout of frames; the attributes are:
name: name of the file to be written on the disk;idlist: list of the subplot to be displayed in the figure;title: add a title on the top of the figure;nbrow: impose a number of rows of the layout of the subplots;nbcol: impose a number of columns of the layout of the subplots;format: format of the file to be written on the disk, "pdf" (default) or "png"; Other formats could be chosen (eps, ps, svg,...), but the pdf generation with pdflatex will not be possible in this case;figsize: width x height in inches; defaults to (4,4);dpi: resolution; defaults to 200 if format is set to pdf; or to 800 if format is set to png; only customizable for png format.The name and idlist attributes are mandatory.
In order to draw curves of experimental or analytical data, the <measurement markup should be used with the markup <plot> as illustrated below:
The two mandatory attributes are:
file: name of the file to be read on the disk;path: path of the directory where the data file is located. The path can be omitted (path=""), and in this case, the file will be searched recursively in the directories of the considered study.In order to draw horizontal and vertical error bars, it is possible to specify in the markup <plot> the attributes xerr and yerr respectively (or xerrp and yerrp). The value of these attributes could be:
In order to draw curves of probe data, the <probes> markup should be used as a child of a markup <case> as illustrated below:
The attributes are:
file: name of the file to be read on the disk;spids: id of the subset of curves (i.e. markup <subplot>) where the current curve should be plotted;dest: id of the results directory in the destination:dest="", and the value will be updated after the run step in the destination directory (see [output](Output files) section).code_saturne smgr -f sample.xml -c for example), the id of the results directory in the destination must be given (for example dest="20110706-1523"), but if there is a single results directory in the RESU directory of the case, the id can be omitted: with dest="", the id will be completed automatically.The file, spids and dest attributes are mandatory.
The parameters file allows executing additional Matplotlib commands (i.e Python commands), for curves (2D lines), or subplot, or figures. For every object drawn, smgr associate a name to this object that can be reused in standard Matplotlib commands. Therefore, children markup <plt_command> could be added to <plot>, <subplot> or <figure>.
It is possible to add commands with the Matlab style or Python style. For the Matlab style, commands are called as methods of the plt module, and for the Python style commands or called as methods of the instance of the graphical object.
Matlab style and Python style commands can be mixed.
line and lines (with line = lines[0]).ax:The post-processing is activated if the option -p, --post is present in the command line.
SMGR can include files into the final detailed report. These files must be in the directory of results either in the destination or in the repository. The following example shows the inclusion of two figures from the destination, and the repository:
Text files,  source files, or graphical (PNG, JPEG, or PDF) files may be included.
source files, or graphical (PNG, JPEG, or PDF) files may be included.
In the parameters file, input files are defined with markups <input> as children of a single markup <case>. The attributes of <input> are:
file: name of the file to be includedrepo or dest: id of the results directory either in the repository or in the destination;dest=""; the value will be updated after the run step in the destination directory (see output section).RESU directory (either in the repository or in the destination) of the case, the id can be omitted: with repo="" or dest="", the id will be completed automatically.The file attribute is mandatory, and either repo or dest must be present (but not both) even if it is empty.
SMGR produces several files in the destination directory:
studymanager.log: standard output of SMGR;smgr_<name>.xml: udpated SMGR parameters file, useful to restart the script if an error occurs;Only available with option -r, --run:
run_case.log: generated in all STUDY/CASE/RESU/run_id folders, summary of the creation and the run of the case;Only available with option-p, --post:
report_figures.pdf: list of the generated figures;smgr_post_pro.log can be found in case of error during post-processing;make_pdf.log and report_figures.tex/.log/.aux can be found in case of error during generation of report_figures.pdf.Only available with option--report:
write-up.pdf : description report file in STUDY/REPORTSMGR can produce or modify several files in the repository directory:
smgr_<name>.xml: update file with -u, --update-smgr option;setup_<name>.xml: update all xml files in STUDY/CASE/DATA/ with -x, --update-setup option;smgr_compilation.log: summary of the compilation with -t, --test-compilation option.After the computation of a case, if no error occurs, the attribute compute is set to "off" in the copy of the parameters file in the destination. It allows a restart of SMGR without re-run successful previous computations.
The opening and closing markup for comments in XML are <!-- and -->. In the following example, nothing from the study MyStudy2 will be read:
It is possible to use raw commands:
You have to use the raw command subplots_adjust:
When there is a typo in the parameters file, SMGR indicates the location of the error with the line and the column of the file:
The less-than < and greater-than > symbols are among the five predefined entities of the XML specification that represent special characters.
In order to have one of the five predefined entities rendered in any legend, title or axis label, use the string . Refer to the following table for the name of the character to be rendered:
| name | character | description |
|---|---|---|
quot | " | double quotation mark |
amp | & | ampersand |
apos | ' | apostrophe |
lt | < | less-than sign |
gt | > | greater-than sign |
For any of these predefined entities, the XML parser will first replace the string by the character, which will then allow (or Mathtext if is disabled) to process it.
For example, in order to write 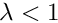 in a legend, the following attribute will be used:
in a legend, the following attribute will be used:
The following raw commands can be used:
The following example shows how to carry out a grid convergence study by running the same case three times and changing the parameters between each run with the help of a preprocessing script.
Here the mesh, the maximum number of iterations, the reference time step and the number of processes are modified, before each run, by the built-in cs_parametric_setup.py script.
The parameters file is as follows:
Recall that the case attribute run_id should be given a different value for each run, while the label should stay the same.
To update in repository a setup based on a script called with the deprecated <prepro> tag, simply copy the contents of that script in the "local functions" section of the optional DATA/cs_user_scripts.py user scripts, renaming main to another chosen name, for example prepro.
Remove the section resembling:
and add the following section in the define_domain_parameters function:
Remember that when modifying mesh or restart file selections, the matching values have already been read and assigned to domain at this point, so the matching domain entries should be modified directly, instead of modifying the XML file.
Also when reading or writing a setup XML file, the path to that file should simply be setup.xml or domain.param, as this function is called directly from the execution directory, and should not modify the upstream setup.
In the SMGR XML file, <prepro> can then simply be replaced with <kw_args>. Only the args attribute is used, so other attributes (label and status) can be removed. Also, the -c or --case arguments commonly used to indicate the matching case are not necessary anymore.
Note also that using the <notebook> and <parametric> tags is simpler for notebook values or options already handled by the cs_parametric_setup.py script, as they require no intervention in cs_user_scripts.py. As usual, the approaches can be mixed, so as to minimize the size of the user scripts.