|
8.2
general documentation
|


|
|
8.2
general documentation
|
|
This page explains how to submit cases on a cluster using the SLURM resource manager with the studymanager tool.
In order to activate the submission of cases on cluster with SLURM, it is necessary to specify at least one of the two following options:
--slurm-batch-size=N: maximum number of cases per batch in SLURM batch mode (50 by default).--slurm-batch-wtime=M: maximum computation time in hours per batch in SLURM batch mode (12 hours by default).For instance, the following command
will submit batch of cases with a maximum of 20 cases per batch and a maximum total computation time of 8 hours. The number of cases per batch could then be inferior to 20 if the total computation time exceeds 8h.
In order to compute the total computation time per batch, it is necessary to specify an expected computation time per case (HH:MM) in the smgr xml file (3 hours by default).
In this case, the run Grid1 has an expected computation time of 2 hours and 15 minutes and the one of Grid2 is 5 hours.
SLURM batch files are automatically generated in the folder slurm_files in destination. The following file is an example of a SLURM file used with the SLURM batch mode.
Batch cases which require 6 or more processes will be executed in exclusive mode (i.e. no other submission will run on the node).
Additional SLURM batch parameters can be also specified at run time using the --slurm-batch-arg option. This option only takes into account one argument at a time. For example, to add the "exclusive" and send an e-mail notification use the following command-line option: --slurm-batch-arg=--exclusive --slurm-batch-arg=--mail-user=name.last@email.com
wckey argument should be defined. It can be done by either using --slurm-batch-arg=--wckey=<key> during run time, or by setting an environment variable with the following command: export SBATCH_WCKEY=<key>.All ouput and error files are also in the folder slurm_files in destination.
Job-dependencies are defined automatically such that blocks of dependency level M will wait until all blocks of level M-1 are successfully finished.
Three methods are available to define a dependency between cases:
-r or --restart argument <depends> node to a case in SMGR parameter file : Dependencies defined using a <depends> node have priority over those deduced from parametric arguments. They both have priority over restarts in code_saturne data settings.
In the rare cases where dependencies are not related to restarts, the <depends> approach allow fine-grained control. In other cases, dependencies are deduced from restart definitions, so no additional user settings are needed.
The state analysis is automatically added with the slurm batch mode. This final batch will depend on all previous submissions. It can also include postprocessing and comparison steps if these options are activated.
In the following example, a list of 8 cases is launched in SLURM batch mode:
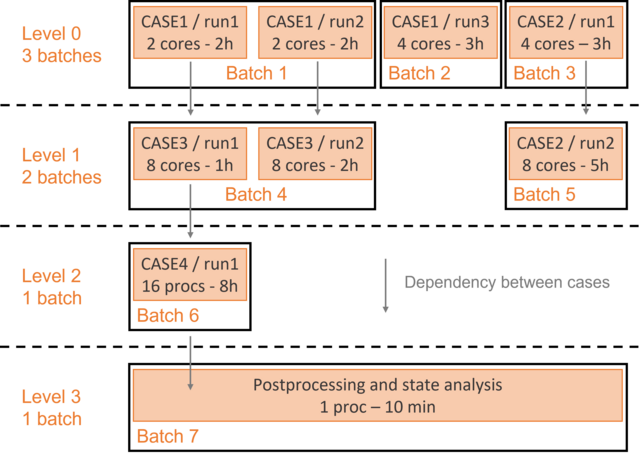
Here are some explanations on cases allocation per batch :